Kirjoittaja: Anniina Sallinen. Teksti perustuu 16.2.2022 pidettyyn jäsenetuwebinaariin.
MLOps on joukko käytänteitä, jotka pyrkivät automatisoimaan ja suoraviivaistamaan koneoppimisjärjestelmien kehitystä ja ylläpitoa. Googlen määritelmän mukaan MLOpsin harjoittamiseen kuuluu muun muassa testauksen, julkaisemisen ja infrastruktuurin hallinnan automatisointi. Sekä Googlen että Valohain määritelmän mukaan MLOps-käytänteiden on syytä olla esillä kehitysvaiheesta tuotantoon viemiseen. Joskus törmää siihen, että MLOpsista puhutaan vain koneoppimismallien tuotantoon viennistä.
Jotta MLOpsia olisi helpompi ymmärtää, pitää ensin ymmärtää, miltä koneoppimismallien kehityskaari yleisesti ottaen näyttää. Alla on karkea kuvaus siitä, miten koneoppimismalleja usein kehitetään, ja miten työ jakautuu datatieteilijöiden ja muiden, kuten ohjelmistokehittäjien, välillä.
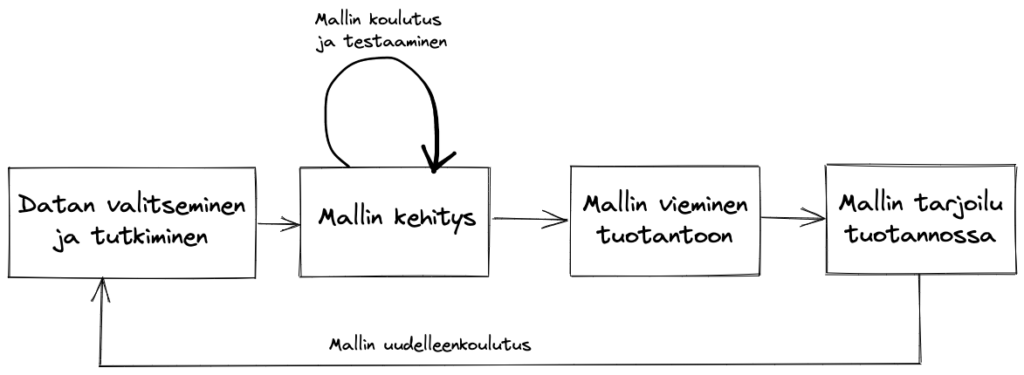
Piirroksen kaksi ensimmäistä laatikkoa liittyvät hyvin vahvasti kehitysvaiheeseen.Ne tekee datatieteilijä esimerkiksi Jupyter Notebookissa käyttäen Pythonia tai R-ohjelmointikieltä. Kaksi jälkimmäistä laatikkoa taas ovat usein jonkun muun kuin datatieteilijän vastuulla.
Datan valitsemisvaiheessa dataa voidaan yhdistellä monista eri lähteistä, esimerkiksi object storagesta ja tietovarastosta. Yhdistelemällä dataa voidaan koostaa featuret, eli ne tekijät, joiden uskotaan selittävän ennustettavaa tekijää. Tässä vaiheessa datasta tutkitaan esimerkiksi arvojen jakaumaa, kuinka paljon data sisältää puuttuvia arvoja, minkälaisia arvoja datassa voi olla ja löytyykö sieltä poikkeavia arvoja. Työ sisältää paljon datan esittämistä graafisessa muodossa esimerkiksi Pythonin seaborn- tai pyplot-kirjastojen avulla.
Mallin kehitysvaiheessa dataa voidaan jalostaa tuottamalla uusia featureita olemassa olevien perusteella ja data jaetaan koulutus-, testi- ja validointidataan. Datasta myös siivotaan pois poikkeavat arvot, ja puuttuvia arvoja sisältävät rivit joko poistetaan datajoukosta, tai ne korvataan esimerkiksi käyttäen mediaania tai moodia. Tähän vaiheeseen liittyy myös hyperparametrien ja koneoppimisalgoritmin valinta, ja kokeiluja eri algoritmeilla ja hyperparametreilla voidaan ajaa useaan kertaan. Mallin koulutukseen käytetään valittua koulutusdataa. Koulutuksen lopputuloksena syntyvien mallien suoriutumista voidaan testata käyttäen testidataa, ja kun lopullinen algoritmi on valittu, koulutetun mallin suoriutumista voidaan testata ennen näkemättömällä datalla käyttäen validointidataa. Mallin koulutus on usein hidasta, etenkin jos datatieteilijä ajaa koulutusajoja omalla tietokoneella sen sijaan, että hän hyödyntäisi pilvessä sijaitsevaa laskentakapasiteettia.
Kun datatieteilijä on tyytyväinen koulutettuun malliin, on edessä sen vieminen tuotantoon. Tuotantoon vietävä malliartifakti on usein mukana versionhallinnassa, tai se on esimerkiksi object storagessa kuten AWS:n S3:ssa. Usein mallin vie tuotantoon joku muu kuin datatieteilijä, esimerkiksi ohjelmistokehittäjä, joka rakentaa infrastruktuurin ja implementoi mallin ennusteiden tarjoilun. Tämä voi tarkoittaa eräajoa, joka tallentaa ennusteet tietokantaan, tai APIa, jota kutsuessa muodostetaan ennuste ja palautetaan kutsun tehneelle osapuolelle. Sama osapuoli, joka vie mallin tuotantoon rakentaa usein myös monitoroinnin sille. Rakennettu monitorointi on usein rakennettu samaan tyyliin kuin perinteisen rajapinnan monitorointi: järjestelmästä monitoroidaan esimerkiksi suoritusaikaisia virhetilanteita, rajapintaan tulevien pyyntöjen määrää ja latenssia. Tämä ei kuitenkaan usein riitä, vaan operationaalisen monitoroinnin lisäksi tulisi monitoroida esimerkiksi mallin tarkkuutta. Jos mallin tarkkuutta halutaan tarkastella tuotannossa, sen tarkastelu tehdään usein pistemäisesti esimerkiksi kirjoittamalla ad hoc -skriptejä tai tutkimalla dashboardia. Usein ennusteista ei kuitenkaan edes kerätä palautetta, jolloin mallin monitorointia ei käytännössä tehdä lainkaan.
Jos mallin suoriutumista tuotannossa ei aktiivisesti tarkkailla, ei tiedetä milloin on oikea aika uudelleenkouluttaa malli. Mallin uudelleenkoulutus hoidetaan sitten esimerkiksi, jos käytettäväksi saadaan uutta dataa, jonka uskotaan parantavan mallin toimintaa, tai olemassa olevaan dataan saadaan tuodaan uusi sarake, josta voidaan jalostaa uusi feature. Joskus datatieteilijä haluaa myös kokeilla uutta koneoppimismenetelmää tai -algoritmia, kuten syväoppimista ja päättää kouluttaa mallin uudelleen tällä menetelmällä. Yksi syy uudelleen kouluttamiselle on myös se, että joku ulkopuolinen taho huomaa, ettei malli toimi kunnolla. Esimerkiksi jos mallin tehtävänä on ennustaa, keneen asiakkaaseen kannattaa ottaa yhteyttä lisämyynnin toivossa, ja toinen järjestelmä automatisoi toimintaansa ennusteiden perusteella, voivat esimerkiksi tämän toisen järjestelmän käyttäjät ja kehittäjät huomata, että malli tuottaa ennusteita, joiden mukaan ketään ei kannata kontaktoida. Tai päinvastoin, kaikkia pitäisi kontaktoida. Joskus malleja myös koulutetaan vain koska malli on esimerkiksi ollut jo kauan tuotannossa, eikä kenelläkään ole oikein tietoa kuinka hyvin se suoriutuu.
MLOpsin hyödyt
MLOpsin hyödyt ovat pitkälti samankaltaisia kuin DevOpsinkin. Esimerkiksi versiointi ja metadatan kerääminen ovat toistettavuuden edellytyksiä. MLOpsiin sisältyy koodin ja konfiguraatioiden versiointi, kuten DevOpsiinkin, mutta lisäksi MLOpsiin kuuluu myös mallin ja datan versiointi, ja metadatan kerääminen mallin koulutuksesta. Tämä tarkoittaa siis sitä, että malli voidaan tuottaa samalla tavalla eri ympäristöissä, ja malli voidaan tarpeen vaatiessa tuottaa uudelleen samalla tavalla. Se auttaa myös sellaisissa tilanteissa, joissa tuotannossa huomataan virhe mallissa, ja mallin kouluttamista on tarpeen debugata.
Toinen hyöty, eli näkyvyys tarkoittaa sitä, että pystymme vastaamaan kysymyksiin siitä, miten malli on koulutettu, miten sitä on testattu, koska viimeisin versio on viety tuotantoon ja pitäisikö malli uudelleenkouluttaa. Kun mallin koulutus on automatisoitu, ja siitä kerätään metadataa, vastaus kysymyksiin on löydettävissä helposti. Näkyvyys siihen, pitäisikö malli uudelleenkouluttaa, saavutetaan mallin monitoroinnilla.
Mallin monitorointi auttaa meitä myös luottamaan siihen että malli toimii tuotannossa ja tuottaa arvoa. Käytetty monitorointityökalu voi lähettää automaattisesti hälytyksen, kun mallin tarkkuus laskee alle sallitun rajan, tai kun datan jakauma on muuttunut merkittävästi. Luotettavuutta lisäävät myös automatisoidut testit, jotka ajetaan ennen kun uusi malli viedään tuotantoon, ja feature storen käyttö taas edistää sitä, että jokaisen mallin käyttämät featuret on laskettu samalla tavalla ja että mallin koulutus- ja tarjoiluvaiheen data eivät eroa toisistaan.
Versioinnin ja metadatan tallennuksen ansiosta kaikilla tiimiläisillä on sama koodi ja tieto mallista ja sen datasta, joten MLOpsin voidaan sanoa myös edistävän yhteistyötä ja tiedon jakamista.
Miksei sitten vain DevOps? MLOps pyrkii omaksumaan monia sovelluskehityksen hyviä käytänteitä ja sovittamaan niitä koneoppimiskehitykseen sopivaksi. Koneoppimisjärjestelmissä ja perinteisemmissä järjestelmissä, esimerkiksi web-sovelluksissa, on joitakin merkittäviä eroja. Koneoppimismalli on koneoppimisjärjestelmien toiminnan ydin, web-sovelluksissa sen ydin on koodi, joka suoritetaan. Koneoppimismallit ovat matemaattisia malleja, jotka pyrkivät muodostamaan käsityksen ympäröivästä maailmasta sille syötetyn datan perusteella. Tämä johtaa siihen, että mikäli mallin tekemät oletukset maailmasta eivät pidäkään paikkaansa, malli ei toimi tuotannossa. Jos siis ajamme mallille testit ennen tuotantoon vientiä, onnistuneesti ajetut testit eivät takaakaan sitä, että malli toimii tuotannossa. Järjestelmien toimintaa siis mitataan hyvin eri tavoin: web-sovellus toimii, jos se suorittaa koodin onnistuneesti ilman virheitä, määritelmien mukaisesti, ja koneoppimismalli toimii, jos se tuottaa tarpeeksi tarkkoja ennusteita. Nämä erot voivat myös johtaa siihen, että tuotannossa olevan mallin toimivuus voi ajan mittaan muuttua. Ei siksi, että mallissa itsessään olisi muutoksia, vaan koska maailma sen ympärillä muuttuu.
Myös koneoppimismallien kehitys on hyvin erilaista kuin web-sovelluksen kehitys. Kokeiluja eri algoritmeilla ja hyperparameterilla voidaan ajaa useaan otteeseen, ennen kun lopputulokseen ollaan tyytyväisiä. Näiden kokeilujen lopputuloksena syntyy malliartifakti, joka on itsessään matemaattinen malli, ja joka on se toiminnallinen osa, joka deployataan tuotantoon.
Automatisoitu koneoppimisputki
Jos palataan takaisin alkuun, jossa esiteltiin koneoppimismallin kehityskaarta, ja lisätään siihen MLOpsin elementtejä, voidaan saada esimerkiksi seuraavanlainen automatisoitu koneoppimisputki:
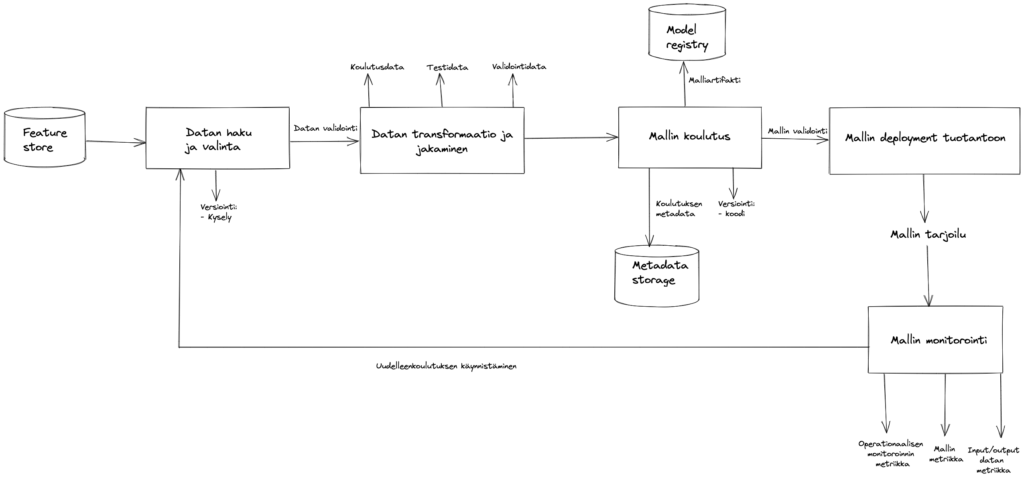
Tässä koneoppimisputkessa jokainen vaihe on siis automaattisesti suoritettavissa, ja jokaisesta vaiheesta tallennetaan tietoa joko versionhallintaan tai metadata storeen. Kuvassa näkyvät laatikot voivat olla itsenäisiä ajoja esimerkiksi Docker-kontissa, ja koko putken orkestrointi tapahtuu myös automaattisesti. Koulutuksessa käytettävä data haetaan feature storesta ja haettu data validoidaan automaattisesti. Sille suoritetaan tarvittavat transformaatiot ja se jaetaan automaattisesti koulutus-, testi- ja validointidataan. Mallin automaattisesta koulutuksesta syntyvä malliartifakti tallennetaan model registryyn eli mallirekisteriin ja metadata mallin koulutuksesta tallennetaan metadata storageen. Mallin validoinnin jälkeen uusi malli, tai uusi versio vanhasta mallista voidaan automaattisesti deployata tuotantoon, jossa se tuottaa ennusteita. Mallin monitorointi tuotannossa sisältää luonnollisesti operationaalisen monitoroinnin, mutta myös mallin suoriutumisen monitoroinnin, ja vähintäänkin sen tuottamien ennusteiden monitoroinnin.
MLOps -alustoja ja työkaluja
Vaikka MLOps ei olekaan vielä vakiintunut alalla, on tarjolla sekä avoimen lähdekoodin työkaluja ja alustoja että kaupallisia MLOps tuotteita. Oma näkemykseni onkin, että ilman hyvää syytä ei kannata lähteä toteuttamaan omaa ratkaisua alusta alkaen. Moni tuotteista on ehtinyt jo saavuttamaan melko laajan suosion ja kypsyyden, ja niitä kehitetään eteenpäin kaiken aikaa. Sopivia työkaluja tai alustoja miettiessä ja vertaillessa kannattaa ottaa huomioon ainakin olemassa oleva infrastruktuuri, tuotteen helppokäyttöisyys, mitä ominaisuuksia työkalulta kaipaa eli haluaako yhden alustan tarjoavan kaiken vai koostaako eri palasista kokonaisuuden itse, haluaako esimerkiksi pilviagnostisen vaihtoehdon ja tietysti yksi tärkeimmistä kriteereistä, eli työkalun hinta ja käytettävissä oleva budjetti.
Monia MLOps osa-alueita kattavia tuotteita ovat esimerkiksi Amazon Sagemaker, kotimainen tarjoaja Valohai ja avoimen lähdekoodin vaihtoehto MLFlow. DataBricksin koneoppimispuoli sisältää myös hallinnoidun MLFlown. Lisäksi markkinoilta löytyy pelkästään feature storea tarjoava Tecton, ja neptune.ai, jonka tuote on metadata store. Koko koneoppimisputkea tarjoaa myös Netflixiltä lähtöisin oleva, avoimen lähdekoodin kirjasto Metaflow.